Web Scraper
⭐ the repo if you like this project 😀
You can check the live feed from [here](https://youtu.be/NvXpo41vNrQ) as well. 😀
You can check the live feed from [here](https://youtu.be/NvXpo41vNrQ) as well. 😀
What is a Web-Scraper?
According to Wikipedia, “ Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. The web scraping software may directly access the World Wide Web using the Hypertext Transfer Protocol or a web browser. “
Used languages & framework:



Run the scrapper
- Clone the repository
-
Using SSH
git clone git@github.com:FahimFBA/Web-Scraper.git -
Using HTTPS
git clone https://github.com/FahimFBA/Web-Scraper.git
-
- Go to the Web-Scraper directory
cd Web-Scraper
- Run the project using the following command
npm run start
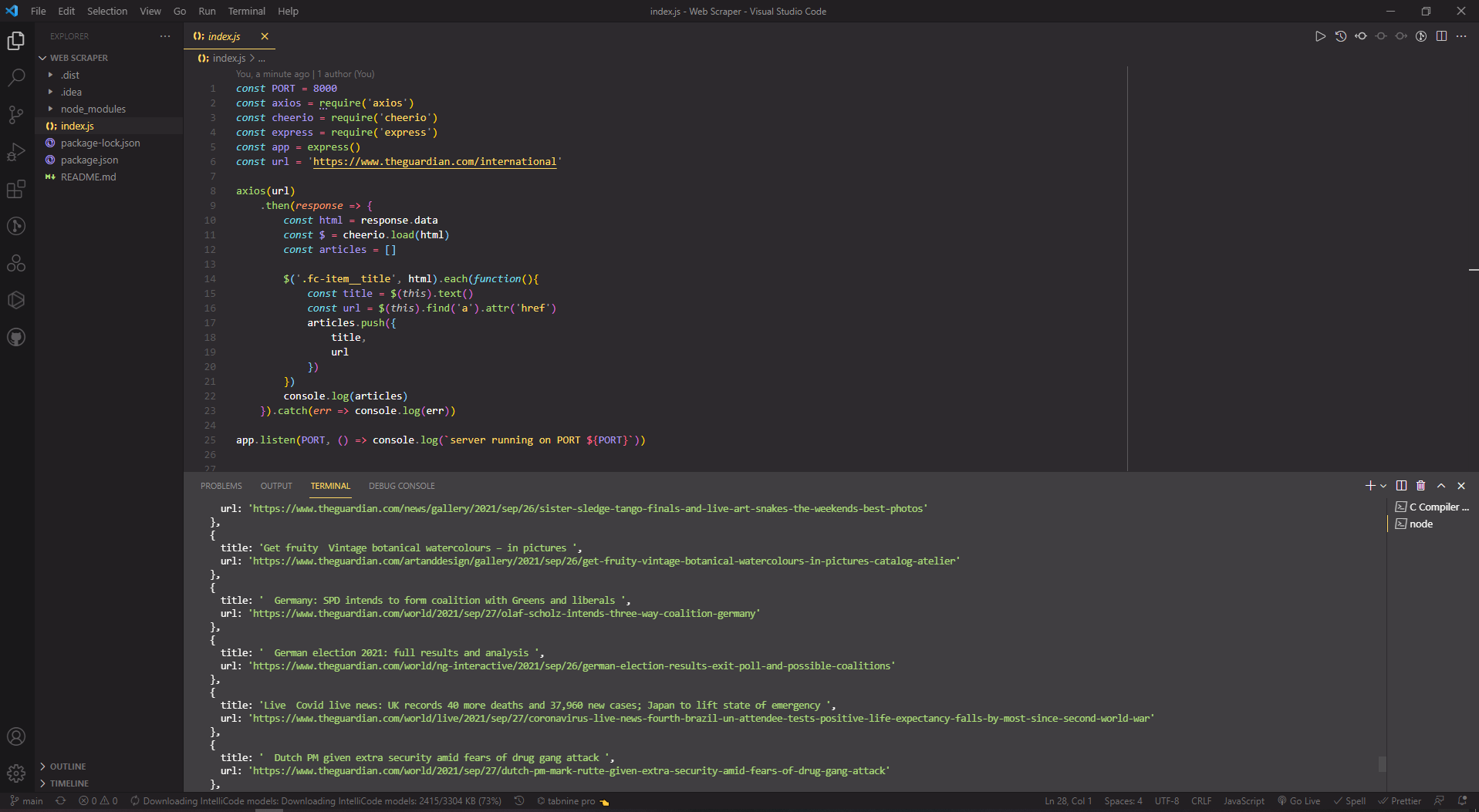
By default, it would scrap from The Guardian as I used The Guardian to experiment with the web scrapper.
To experiment on different websites, change the url in the index.js and customize the class in the axios as well.
Output (Using VS Code)
Special thanks goes to Ania Kubów